
맵리듀스란 무엇인가?
Updated:
맵리듀스
1. 정의
→ 분산된 각 노드에 분산되어 있는 데이터를 하나의 노드에 저장된 것 같이 처리하는 기술로서 맵과 리듀스 라는 2개의 메소드로 구성되어 있다
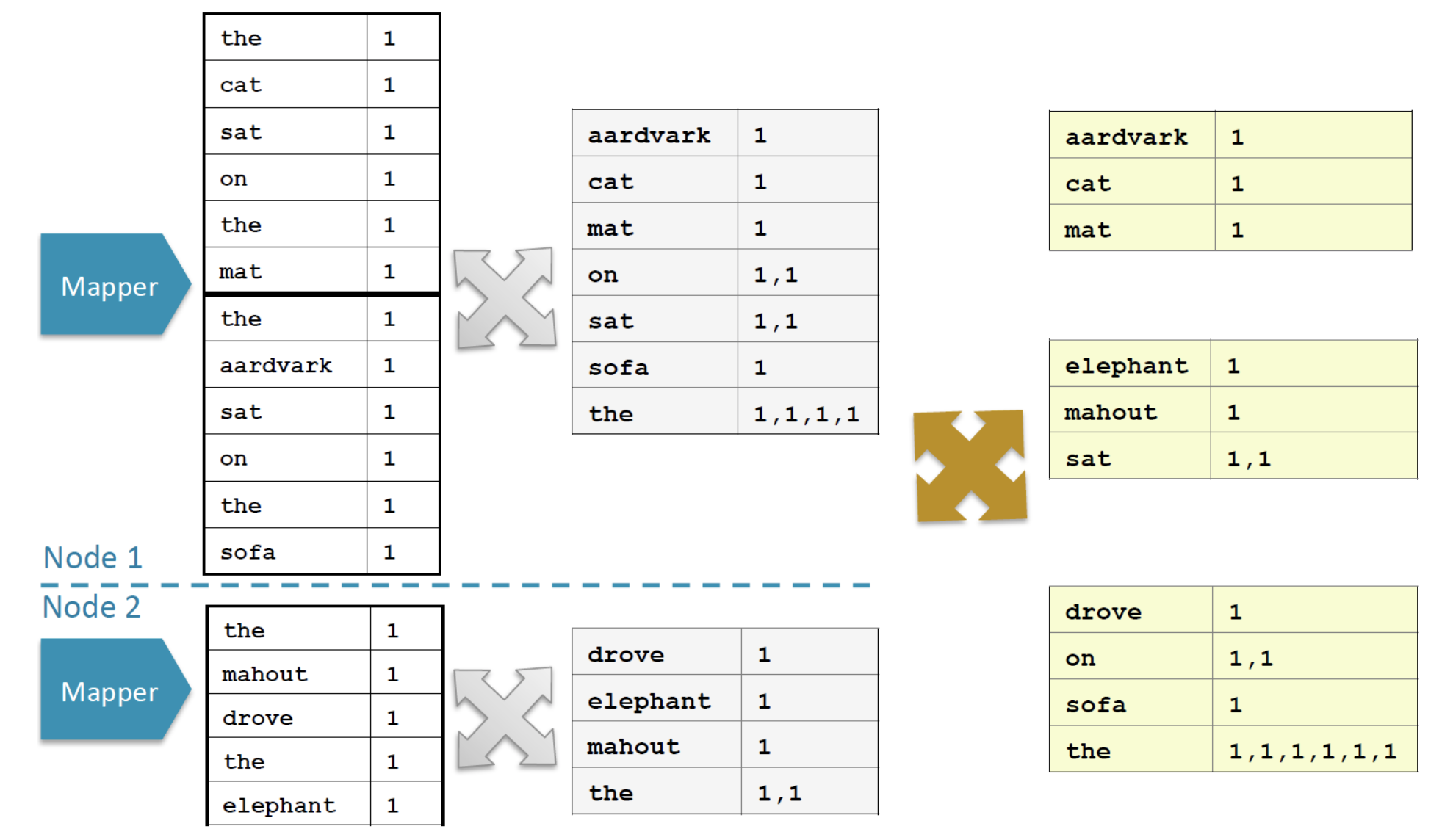
- 맵: 흩어져 있는 데이터를 연관성 있는 데이터 들로 분류하는 작업으로 key, value의 형태로 저장된다
- 리듀스: 맵에서 출력된 데이터에서 중복을 제거하고 원하는 데이터를 추출하는 최종 작업이다
- 잡: 클라이언트가 수행하려는 작업 단위라고 보면 된다. 입력데이터, 맵리듀스 프로그램, 설정 정보로 구성되어 있다
2. 특징
-자동으로 분산 및 병렬 처리를 수행함
-장애 허용
-자바로 개발되었기 때문에 맵리듀스 프로그래밍도 자바로 개발함
-Map과 Reduce 기능을 사용할 때 각각 Mapper와 Reducer 객체를 상속받아 사용함
3. 주요처리과정
- Mapper
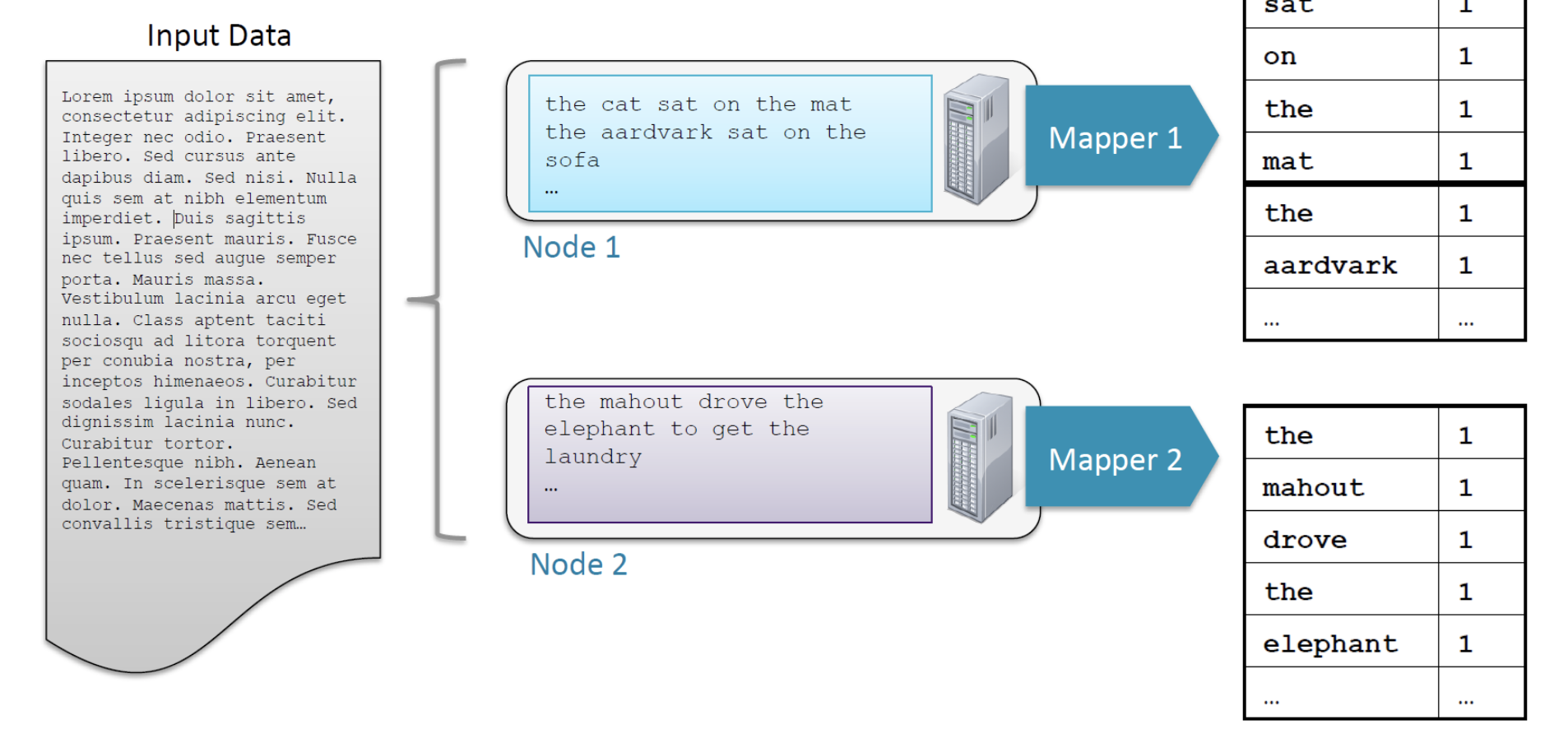
-싱글 HDFS 블록들에 대해 각 맵 작업이 수행됨
-맵 작업들은 대체로 블록이 저장된 데이터 노드에서 실행됨 - Shuffle and Sort
-모든 맵 작업들이 종료될 때 수행하고, 리듀스 작업이 시작하기 전에 종료된다
-맵리듀스 프레임워크에서 자동으로 실행되니 따로 코드 작성할 필요가 없다 - Reducer
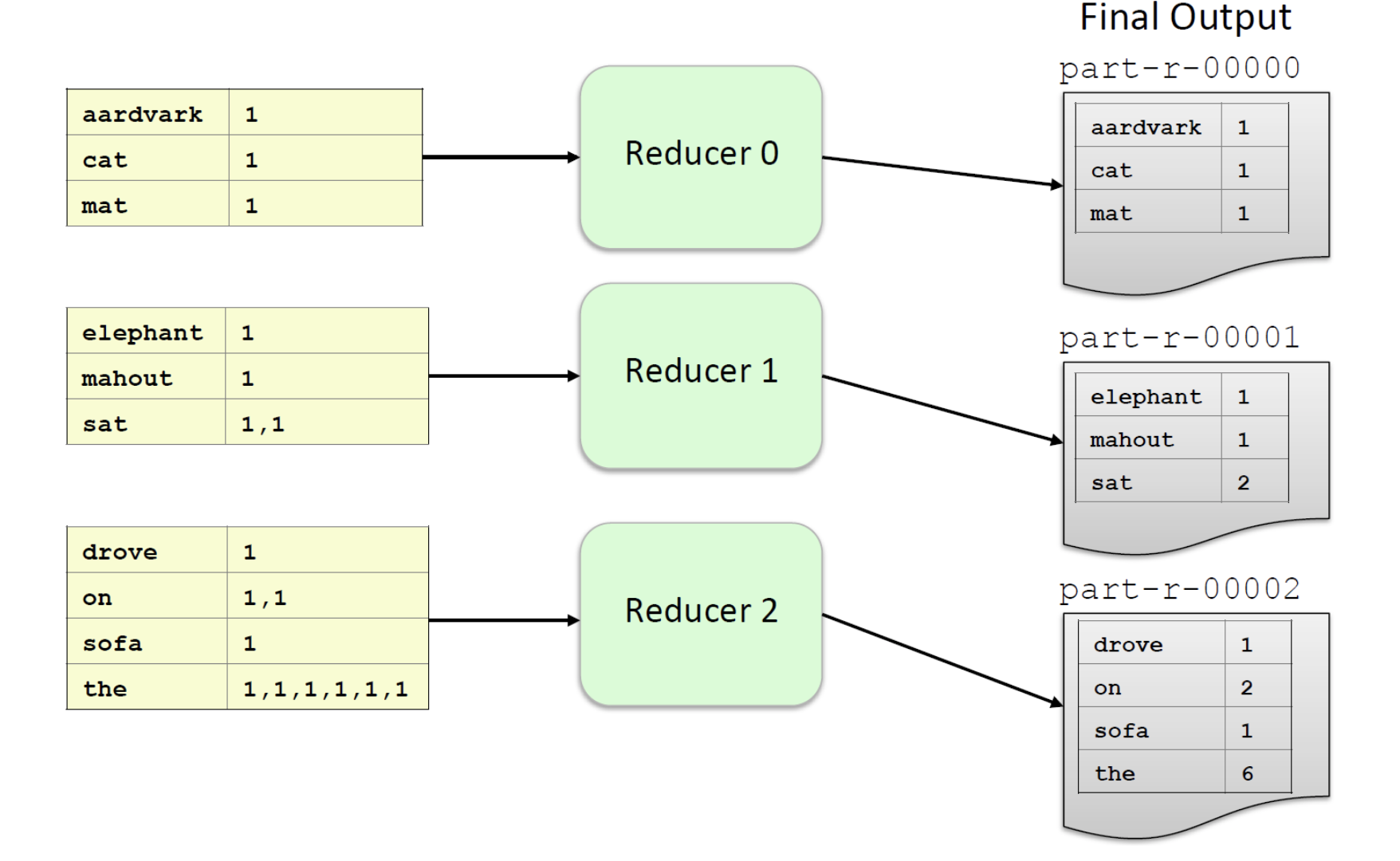
-default값은 1개
-최종 산출물
4. 자바객체중심의 맵리듀스 처리 과정
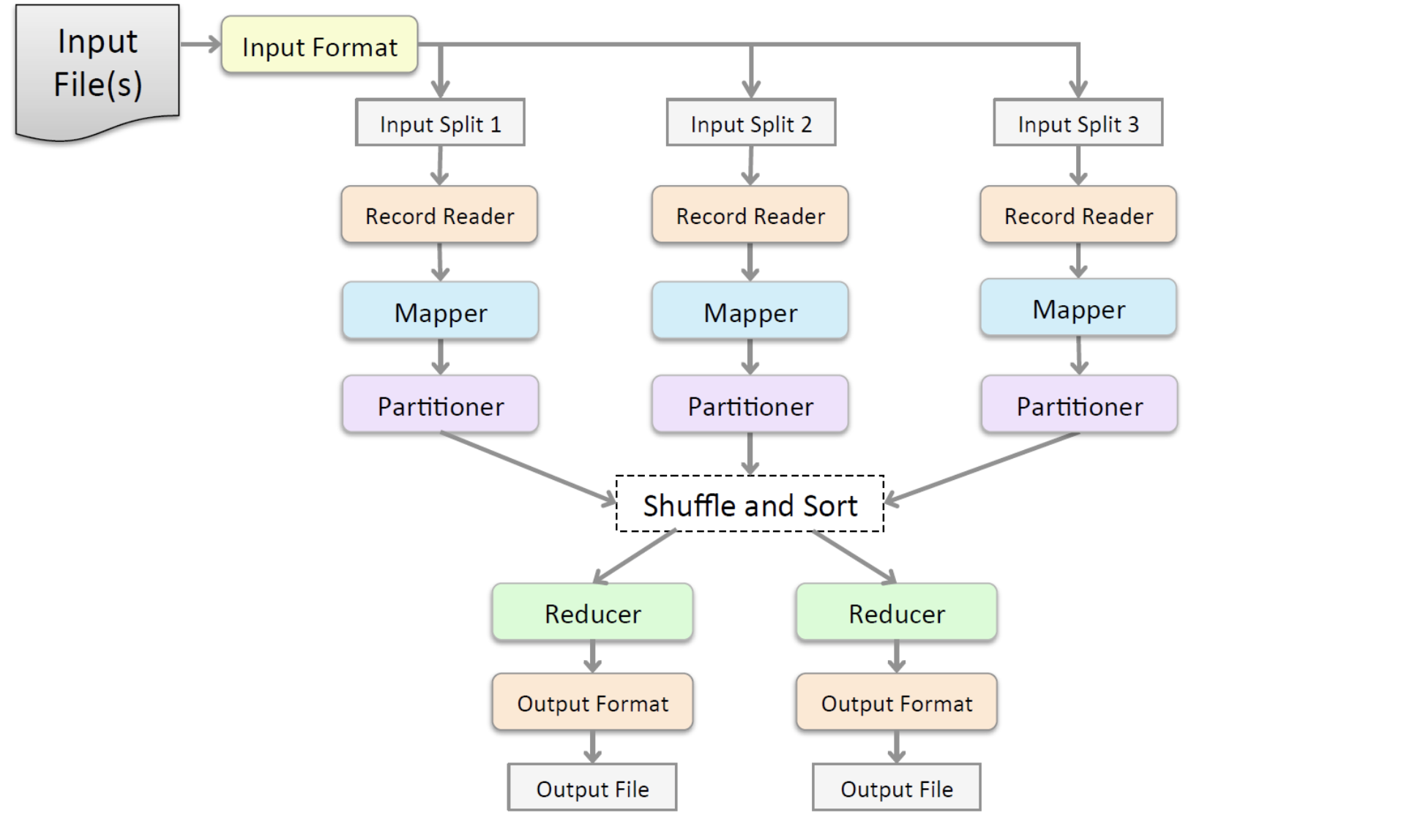
- Input File을 통해 처리할 데이터가 들어오면
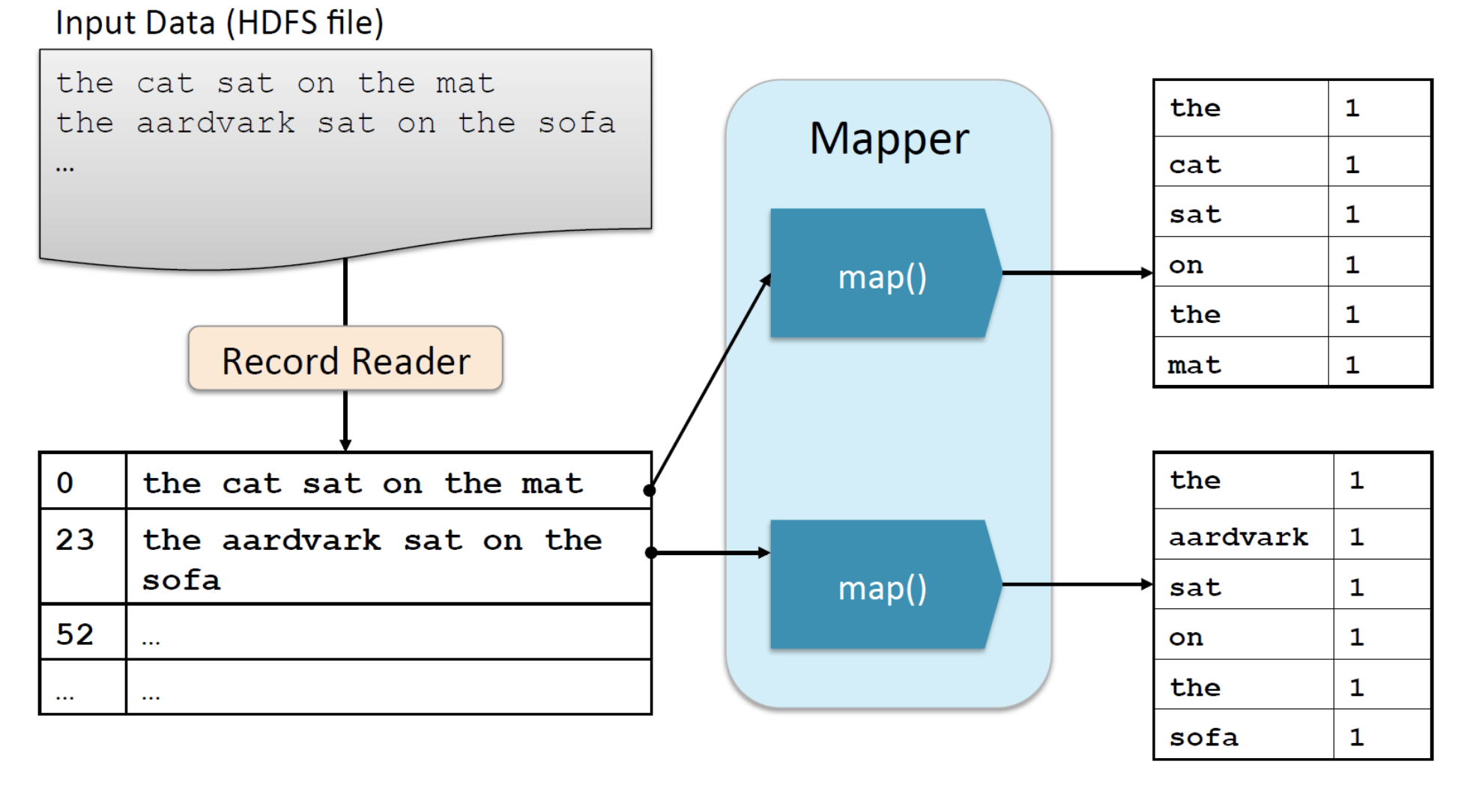
- Input Format이라는 자바 객체를 통해 데이터가 줄별로 나눠진다
- Record Reader라는 자바 객체를 통해 데이터가 자바에서 처리할 수 있는 데이터형태(key, value의 형태로 나타내게 되는데 key에는 배열의 인덱스 값이 들어가고 value에는 실제 데이터값이 들어가게 됨)로 변환되고
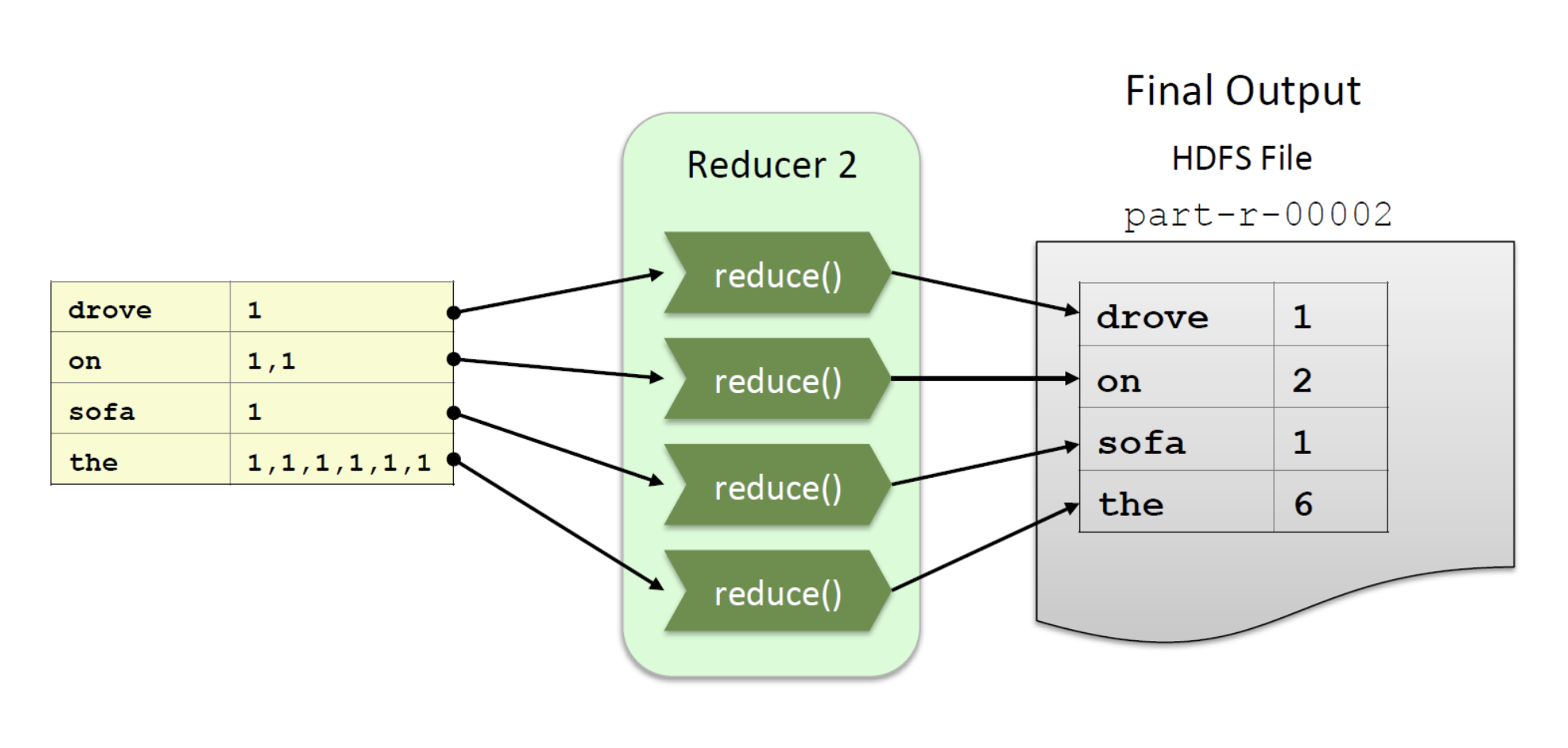
- Mapper는 나눠진 각 줄마다 map() 메서드를 실행시킨다(많은 Mapper들이 병렬로 실행됨)
- 그 후 Shuffle and Sort 과정을 통해 각 노드마다 데이터들을 정렬한 후 노드 상관없이 다시 정렬시키고
- Reducer(default값은 1개지만 여기서는 2개로 예시를 들음)안의 reduce() 메서드를 통해 각각의 나눠진 데이터들을 최종 산출한다
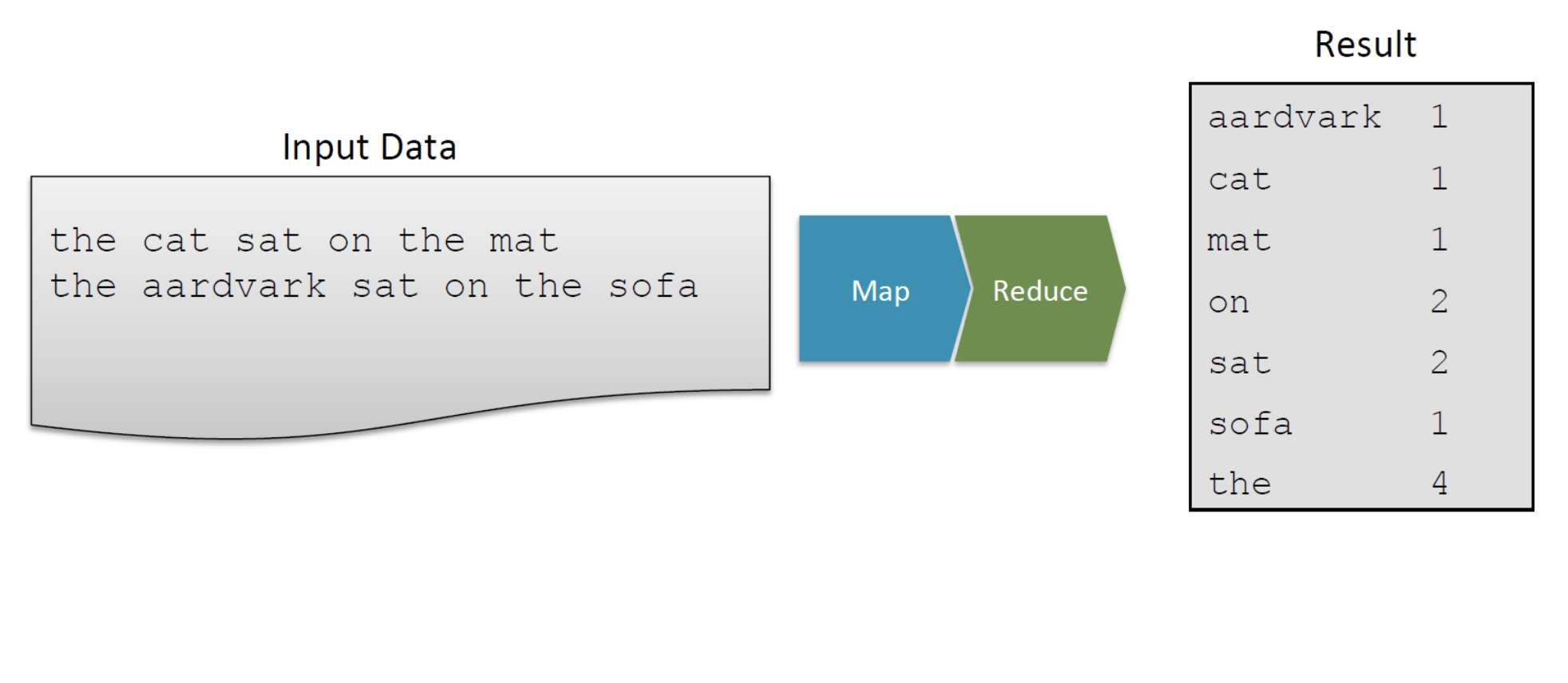
5. 글자 빈도수 세기
Leave a comment